Hot Topics in Chandra Observations of the Solar System
Previous: index Contents Next: Important Dates
Hot Topics in Chandra Observations of the Solar System
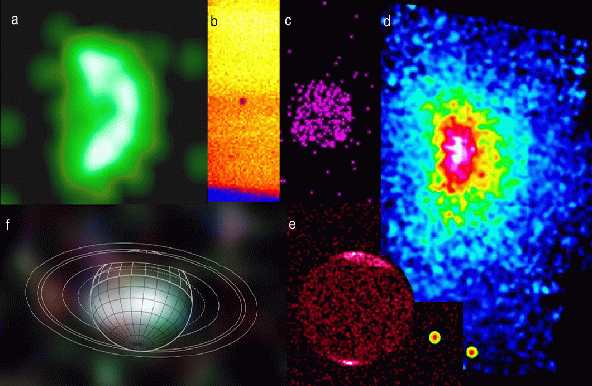 |
| FIGURE 1: A rogues' gallery of nearby X-ray sources. They are
(clockwise from upper left): a) a Gaussian smoothed image of Venus; b)
Titan occults part of the Crab Nebula; c) Mars; d) a slightly smoothed image of Comet Ikeya-Zhang; e) Jupiter from HRC, where the two red/yellow objects in the lower right are ACIS views of Io and Europa montaged onto the figure;
and f) True-color Saturn smoothed to 53. References are given in the
text.
|
X-rays are generally associated with extremely high temperature
phenomena from at least 1 million K up to and beyond 100 million
K. Yet, in the Solar System we detect X-rays from objects with typical
temperatures well below 1000 K. We observe X-rays from a wide variety
of phenomena and under a broad range of conditions. Key production
mechanisms include fluorescence (in which solar radiation directly
excites a neutral atom or molecule) and charge exchange (in which an
electron from a low density neutral is passed to a highly ionized
species in the solar wind). Other production mechanisms include photon
elastic scattering, electron-ion bremsstrahlung and heavy ion
precipitation through a magnetosphere. An exciting aspect of this
research is that several of these processes involve the production of
new X-ray photons in addition to those produced in the solar
corona. Chandra has observed all the planets in the solar system
between Venus and Uranus and well as the Moon and half a dozen
comets. All of the listed production mechanisms have been found to
play a role.
The Moon
The Moon was actually the first target in the
search for Xrays outside of the Earth and the Sun. A sounding rocket
failed to detect scattered solar X-rays from the Moon between 1.5 and
6 keV (Giacconi 1962). The on-board Geiger counter did discover Sco
X-1, so the mission was not a complete loss. X-rays were detected from
the Moon by Apollo using a variety of experiments. ROSAT became the
first telescope to image the Moon in X-rays.
This observation was proof of the cosmological nature of the Xray
background as it was blocked by the dark side of the Moon. Schmitt
(1991) argued that the Moon's X-ray luminosity arises from scattering
of solar X-rays. They also detected faint X-ray emission from the dark
portion of the Moon, which they attributed to solar wind electrons
striking the lunar surface.
Spectra from recent Chandra observations
indicate that the emission from the dark side of the Moon may actually
be geocoronal emission occurring between the Earth and the Moon as
solar wind ions capture electrons from hydrogen atoms in the extreme
upper reaches of the Earth s atmosphere (Wargelin et al. 2004, in
preparation). The Chandra observations of the illuminated portion of
the Moon detect X-ray emission lines from oxygen, magnesium, aluminum
and silicon. The X-rays are now thought to be produced by fluorescence
when solar X-rays bombard the lunar surface.
Comets
Comets are arguably the most surprising X-ray sources in space. Their X-ray
emission was discovered by ROSAT during the apparition of Hyakutake in
1996 (Lisse 1996). With a luminosity of about 1015 erg/sec, Hyakutake
was the third brightest X-ray source in the solar system after the Sun
and Jupiter. Much as in the case of the Moon, the low spectral
resolution of this previous generation of X-ray instruments left the
production mechanism uncertain.
Chandra observed comet C/Linear 1999
S4 in a series of eight 1 ks snapshots on July 14, 2000 (Lisse
2001). The strong oxygen feature in the spectrum obtained by the
Advanced CCD Imaging Spectrometer (ACIS) immediately ruled out all
models except charge exchange as the sole source of the X-ray
production. The best fit models to the data include charge exchange
lines of O VIII, O VII, N VIII, N VI, C VII and C VI overlying a soft
thermal spectrum. Additional comets have since been observed and the
observations have resulted in more lines detected, a better
understanding of comet morphology, and the differences induced by
cometary density, composition, and the speed of the solar wind as well
as cometary rotation.
For all comets, the emission seems to track the
solar wind at the location of the comet. A corollary to this is that
comets around young stars (with mass loss rates which are many orders
of magnitude greater than that of the sun) should have X-ray emission
several orders of magnitude greater than solar system comets. In
addition, young stars may have hundreds of comets proximate to them at
any given time.
Most of the solar system's planets have been observed
by CXO. These observations are challenging because of the relative
motion of the bodies and their optical brightness, which can be
greater than the design limit of the optical blocking filters of the
ACIS.
Venus & Mars
Venus has been unobservable by previous X-ray telescopes, owing both
to its proximity to the Sun and its extreme optical luminosity. To
offset the latter problem, Venus was observed by Dennerl et al. (2002)
using both the ACIS-I array and the Low Energy Transmission Grating
with the ACIS-S array. Lines of carbon, nitrogen and oxygen were
clearly seen. The X-ray emissionextends above the cloud tops and
unlike the optical emission it is clearly limb brightened. The
morphology, luminosity and spectra are consistent with fluorescent
X-ray scattering of solar X-rays by atoms about 110 km above the
surface.
Mars, undetected by ROSAT, was observed in July 2001. Dennerl
et al. (2002) used the ACIS-I detector. Mars is similar to Venus in
that oxygen was detected with a morphology, luminosity and energy
spectrum consistent with fluorescence scattering of X-rays at 80 km
above the Martian surface. Unlike Venus, a weak X-ray signal was
detected extending several radii beyond the planet, which may be the
signature of charge exchange between the solar wind and a large, low
density, atmosphere of neutrals. This may be direct evidence that Mars
is still losing atmosphere to deep space.
Jupiter
Unlike Mars and
Venus, Jupiter had been previously detected in X-rays. Polar emission
was thought to be the product of oxygen and sulfur ions from Io being
transported through the Jovian magnetosphere and then precipitating
through the auroral regions. Jupiter has been subject to multiple
observing campaigns. Using the High Resolution Camera (HRC), Gladstone
(2002) easily detected emission of about 1016 erg/sec from the entire
surface of Jupiter with a strong concentration toward the poles. While
the general surface emission is presumably from scattered solar
X-rays, the polar emission is between the poles and the auroral
regions imaged by HST and various other spacecraft. This means the
material responsible for this emission cannot be from Io as previously
thought and must emanate from more than 30 RJup away. This leaves the
Sun as the probable source of the ions which collide with the Jovian
atmosphere near the poles. The polar emission is seen to pulse with a
45 minute cadence. A search for a 45 minute resonance in the
observation or within Sun-Jupiter interaction has not found a
suspected source for the periodicity.
Elsner et al. (2002) revisited
the early ACIS observations. While the data from Jupiter itself was
uninterpretable, they found X-ray emission from the moons Io and
Europa. They believe this emission comes from bombardment of the
satellites surfaces by hydrogen, oxygen and sulfur in the Io plasma
torus which itself is detectable at about 10% the total luminosity of
Jupiter itself.
Saturn
Saturn was observed in April 2003 (Ness et
al. 2004). Previously Ness & Schmitt (2000) had reported a ROSAT
detection of 22 photons coincident with Saturn in a 5.3 ks
interval. (Only 7.6 photons were expected.) From this, they derived a
flux of about 2 x 10-14 ergs/cm2/sec. In the Chandra observations,
Ness detects over 100 counts above the background. While the Chandra
observation puts the detection of Saturn on firm footing, the observed
flux was 20% the flux expected based on the ROSAT result. Analysis of
these data are ongoing but there is no evidence of polar concentration
nor temporal variability in the signal from Saturn.
There was also a unique observation of Titan passing in front of the
Crab nebula, only a few arc seconds from the Crab pulsar (Mori et
al. 2004, in preparation).
Recent & Upcoming Observations
Two other
planets have also been observed by Chandra?. The Earth was observed in
cycle 4 by Gladstone, Elsner & Waite using the HRC. Following from
their Jovian experience they hypothesize a particle source region near
Earth s magnetopause and auroral entry of heavy solar wind ions due to
high-latitude reconnection. A weak detection is seen in the publicly
available data. Uranus was observed by Metzger in 2002. No source is
obvious in the data. A similar null result was seen from the asteroid
1998 WT 24.
More work is being done on nearby objects. All of the
observations taken to date are photon starved. None of the
observations have been able to take advantage of Chandra's full
resolution due to counting statistics. One cannot clearly identify the
multiple X-ray production mechanisms present in most bodies. During
Chandra's cycle 4, Jupiter was revisited by both HRC and by ACIS
(using a mode specialized to overcome the optical light leak). Current
Cycle 5 approved observations include a more detailed study of the
Earth s north polar cusp, and a two rotation period observation of
Saturn in time for the first Cassini encounter. As a first attempt at
cometary tomography, 2P/Encke was observed for an entire rotation
period.
I have not been the PI on any of these projects, but I thank
the PI's for letting me play in their sandbox.
Scott J. Wolk
References
Dennerl, K. 2002, A&Ap 394, 1119.
Dennerl, K. et al. 2002, A&Ap 386, 319.
Elsner, R. et al. 2002, ApJ 572, 1077.
Giaconni, R. et al. 1962, Phys. Rev. Lett. 9, 439.
Gladstone, G. R. et al. 2002, Nature 415, 1000.
Krasnopolsky, V. et al. 2001, Icarus 160,437.
Lisse, C.M. et al. 1996, Science 274, 205.
Lisse, C.M. et al. 2001, Science 292, 1343.
Ness, J.-U. Schmitt, J.H.M.M. 2000 A&Ap 355, 394.
Ness, J.-U. 2004 A&Ap accepted.
Schleicher, D.G., & Eberhardy C. 2000, I.A.U. Circular 7455.
Schmitt, J.H.M.M. et al. 1991, Nature 349, 583.
Previous: index Contents Next: Important Dates
cxchelp@head.cfa.harvard.edu